React笔记
1. render props
render props 是一种在 React 组件间使用一个值为函数的 props 共享代码的技术,具体说就是一个用于告知组件需要显然什么内容的函数 props
1 | class DataProvider extends React.Components { |
- 优点:数据共享,代码复用,将组件内的 state 作为 props 传递给调用者,将渲染逻辑交给调用者
- 缺点:无法在 return 语句外访问数据、嵌套写法不够优雅
2. React fiber
2.1 React 16 以前的DOM更新流程
- JSX 转 VDOM
- 新旧 VDOM 作比较(老架构是 递归遍历 VDOM,不能中断)
- 递归结束,通知 Renderer(渲染器),将最新的 VDOM 渲染到页面上
2.2 缺点
React 16前,采用的是 递归遍历新旧 VDOM 树做对比,这会存在一个问题:递归时,如果 VDOM树层级很深,那么会长时间占用 JS 主线程,而 JS又是单线程的,且递归又是同步递归的,就会导致页面上的某些交互操作无法响应、动画卡顿等问题。所以为了解决这个问题,React 16后,新增了 Fiber 架构。
2.3 React15和React6架构的区别
React15架构可以分为两层:
- Reconciler(协调器)—— 负责找出变化的组件
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上
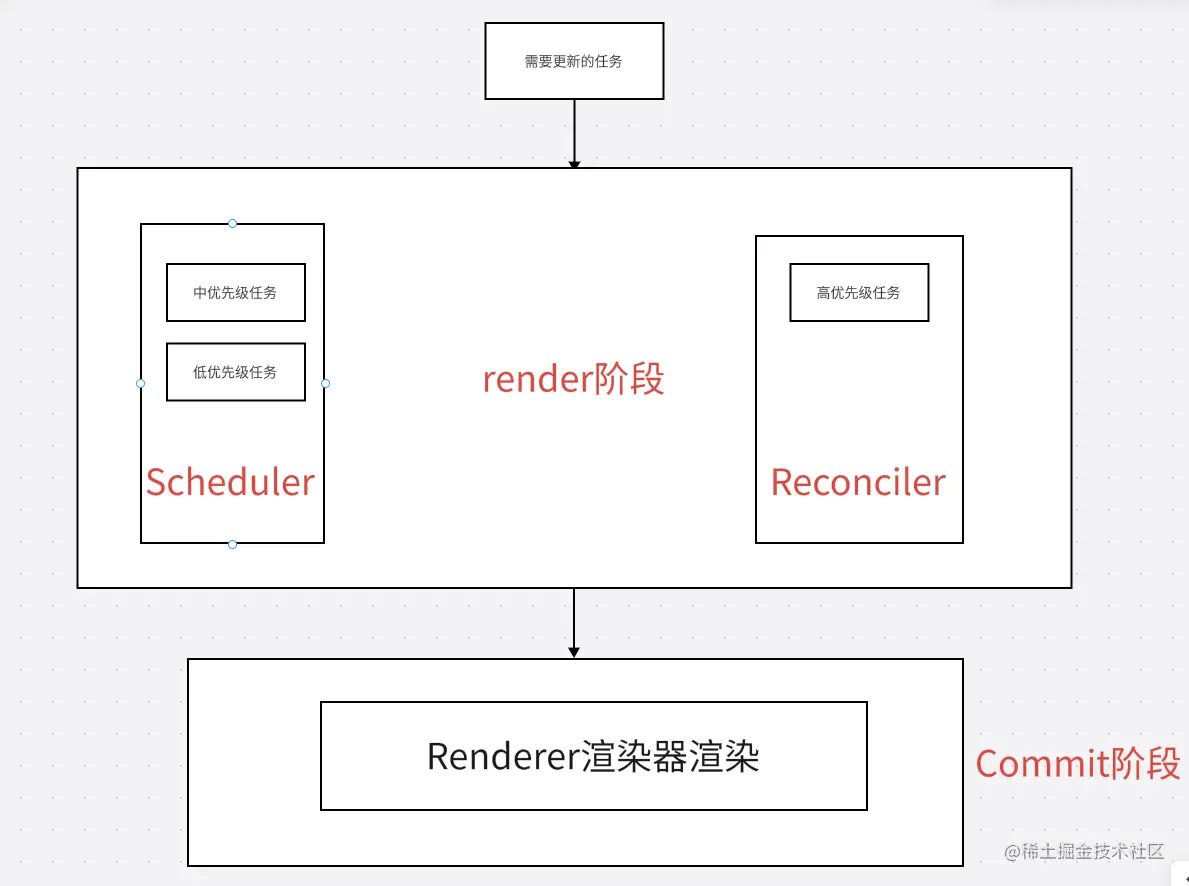
React16架构可以分为三层:
- Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler
- Reconciler(协调器)—— 负责找出变化的组件:更新工作从递归变成了可以中断的循环过程
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上
2.3 Fiber DOM 更新流程
Fiber架构使用协程来优化React应用程序的渲染过程。协程允许在渲染过程中暂停和重新启动组件的渲染,这使得可以优先处理优先级较高的组件,从而提高性能。
- Scheduler 给每个更新任务赋予优先级
- 优先级高的更新任务A,会被推入 Reconciler(协调器),VDOM 转 Fiber,新的 VDOM 和 旧的 Fiber 进行 diff 对比决定怎样生成新的 Fiber 。但如果此时有新的更高优先级的更新任务B 进入 Scheduler,那么 A 就会被中断,B被推入 Reconciler(协调器),当 B 完成渲染后。新一轮的调度开始,A 是新一轮中优先级最高的,那 A 就继续推入 Reconciler 执行更新任务。
- 重复以上的 可中断、可重复 步骤,直至所有更新任务完成渲染。
2.4 Fiber 双缓存
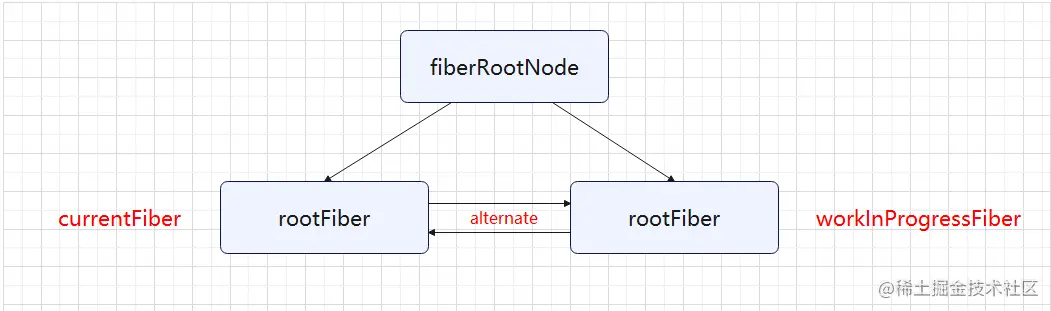
React 更新DOM 采用的是双缓存技术。React 中最多会存在两颗 Fiber树:
- currentFiber:页面中显示的内容
- workInProgressFiber:内存中正在重新构建的 Fiber树。
双缓存中:当 workInProgressFiber 在内存中构建完成后,React 会直接用它 替换掉 currentFiber,这样能快速更新 DOM。一旦 workInProgressFiber树 渲染在页面上后,它就会变成 currentFiber 树,也就是说 fiberRootNode 会指向它。
在 currentFiber 中有一个属性 alternate 指向它对应的 workInProgressFiber,同样,workInProgressFiber 也有一个属性 alternate 指向它对应的 currentFiber。也就是下面的这种结构:
3. React context 的弊端
要想使消费组件进行重渲染,context value 必须返回一个全新对象,这将导致所有消费组件都进行重渲染,这个开销是非常大的,因为有一些组件所依赖的值可能并未发生变化。
3.1 对比useSelector
react-redux useSelector 则是采用订阅 redux store.state 更新,去通知消费组件「按需」进行重渲染(比较所依赖的 state 前后是否发生变化)。
4. 如何解决刷新页面redux数据丢失问题
- 可以使用sessionStorage或者localStorage
- 使用redux-persist插件,但其实本质还是将数据缓存到了sessionStorage或者localStorage
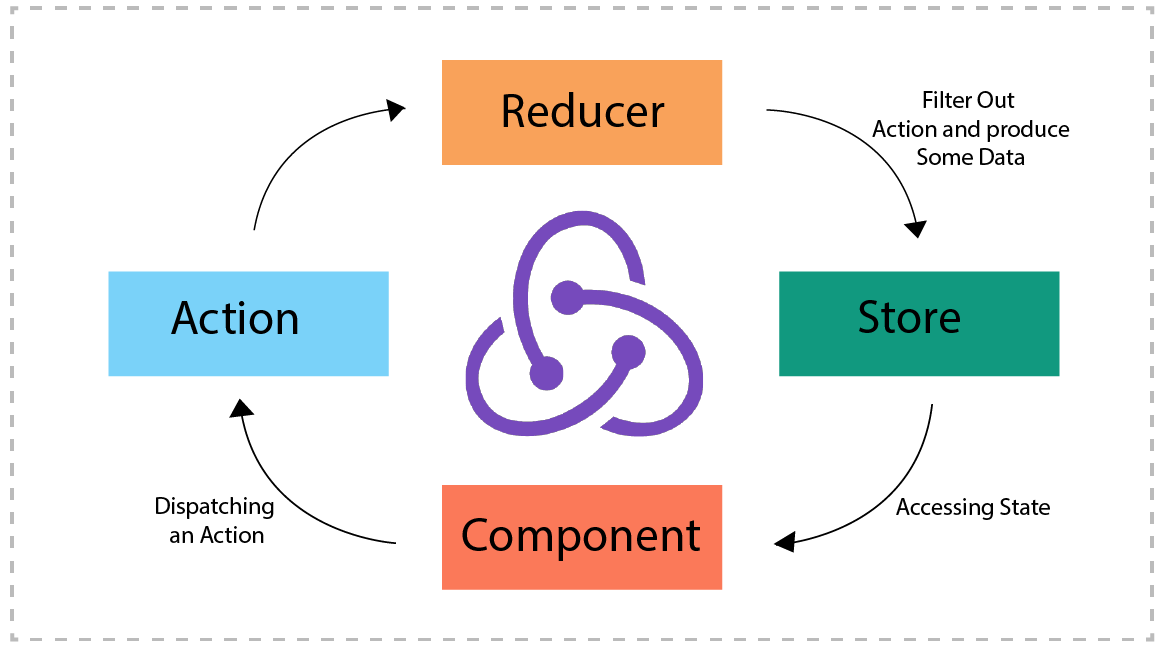
5. connect实现原理
创建一个context,用于将store放入其中
1 | import { createContext } from "react"; |
将store放入context
1 | <StoreContext.Provider value={store}> |
connect实现
1 | import { PureComponent } from "react"; |
6. 为何要在componentDidMount里面发送请求
- 如果要获取外部数据(发送异步请求)并加载到组件上,只能在组件已经挂载到真实的网页上才能做这件事,其他情况是加载不到组件的。
- componentDidMount方法中的代码,是在组件已经挂载到网页上才会被执行,所以可以保证数据的加载。此外,在这个方法中调用setState方法,会触发重新渲染。
- componentWillMount方法中调用setState不会触发重新渲染,所以一般不用来做数据加载。
7. hash和history路由的区别
7.1 SPA与前端路由
SPA(单页面应用,全程为:Single-page Web applications)指的是只有一张Web页面的应用,是加载单个HTML页面并在用户与应用程序交互时动态更新该页面的Web应用程序,简单通俗点就是在一个项目中只有一个html页面,它在第一次加载页面时,将唯一完成的html页面和所有其余页面组件一起下载下来,所有的组件的展示与切换都在这唯一的页面中完成,这样切换页面时,不会重新加载整个页面,而是通过路由来实现不同组件之间的切换。
单页面应用(SPA)的核心之一是:更新视图而不重新请求页面。
优点:
- 具有桌面应用的即时性、网站的可移植性和可访问性
- 用户体验好、快,内容的改变不需要重新加载整个页面
- 良好的前后端分离,分工更明确
缺点:
- 不利于搜索引擎的抓取
- 首次渲染速度相对较慢
7.2 hash
简述
- vue-router 默认为 hash 模式,使用 URL 的 hash 来模拟一个完整的 URL,当 URL 改变时,页面不会重新加载;**# 就是 hash符号,中文名为哈希符或者锚点,在 hash 符号后的值称为 hash 值**。
- 路由的 hash 模式是利用了 window 可以监听 onhashchange 事件来实现的,也就是说 hash 值是用来指导浏览器动作的,对服务器没有影响,HTTP 请求中也不会包括 hash 值,同时每一次改变 hash 值,都会在浏览器的访问历史中增加一个记录,使用“后退”按钮,就可以回到上一个位置。所以,hash 模式 是根据 hash 值来发生改变,根据不同的值,渲染指定DOM位置的不同数据。
特点
- url中带一个 # 号
- 可以改变URL,但不会触发页面重新加载(hash的改变会记录在 window.hisotry 中)因此并不算是一次 HTTP 请求,所以这种模式不利于 SEO 优化
- 只能修改 # 后面的部分,因此只能跳转与当前 URL 同文档的 URL
- 只能通过字符串改变 URL
- 通过 window.onhashchange 监听 hash 的改变,借此实现无刷新跳转的功能。
- 每改变一次 hash ( window.location.hash),都会在浏览器的访问历史中增加一个记录。
- 路径中从 # 开始,后面的所有路径都叫做路由的 哈希值 并且哈希值它不会作为路径的一部分随着 http 请求,发给服务器
7.3 history
简述
- history 是路由的另一种模式,在相应的 router 配置时将 mode 设置为 history 即可。
- history 模式是通过调用 window.history 对象上的一系列方法来实现页面的无刷新跳转。
- 利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。
- 这两个方法应用于浏览器的历史记录栈,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改时,虽然改变了当前的 URL,但浏览器不会向后端发送请求。
特点
- 新的URL可以是与当前URL同源的任意 URL,也可以与当前URL一样,但是这样会把重复的一次操作记录到栈中。
- 通过参数stateObject可以添加任意类型的数据到记录中。
- 可额外设置title属性供后续使用。
- 通过pushState、replaceState实现无刷新跳转的功能。
- 路径直接拼接在端口号后面,后面的路径也会随着http请求发给服务器,因此前端的URL必须和向发送请求后端URL保持一致,否则会报404错误。
- 由于History API的缘故,低版本浏览器有兼容行问题。
8. Redux和Vuex的区别
- Redux使用的是不可变数据,而Vuex的数据是可变的。Redux每次是用新的state去替换旧的state,而Vuex是直接修改。
- Redux 在检测数据变化的时候,是通过 diff 的方式比较差异的,而Vuex其实和Vue的原理一样,是通过 getter/setter来比较的(如果看Vuex源码会知道,其实他内部直接创建一个Vue实例用来跟踪数据变化)
Redux
Vuex
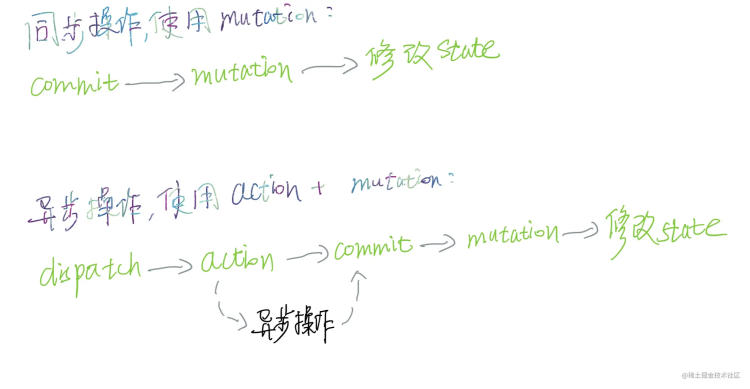
9. Redux中的connect有什么作用
connect负责连接React和Redux:
- 获取state
- connect 通过 context 获取 Provider 中的 store ,通过 store.getState() 获取整个 store tree 上的所有 state
- 包装原组件
- 将 state 和 action 通过 props 的方式传入到原组件中
- 监听 store tree 的变化
- connect 缓存了 store tree 中的 state 的状态,通过当前的 state 和变更前的 state 进行比较,从而确定是否调用 setState 方法触发 Connect 及其自组件的重新渲染
案例:
1 | import { PureComponent } from "react"; |
10. 为什么useState要使用数组而不是对象
useState 返回的是数组而不是对象,原因是为了降低使用复杂度,返回数组的话可以直接根据顺序解构,而返回对象的话想要使用多次就需要定义别名了。比如:
1 | // 第一次使用 |
11. 为什么不能在if和循环里调用Hooks
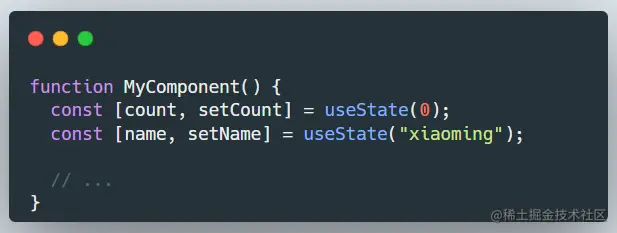
因为React的函数式组件每次渲染都会重新生成状态,且每一次渲染都有一个状态序列,如果在if里调用,就可能导致某次渲染的时候状态序列有缺失,从而出现异常。
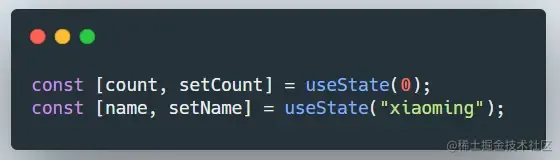
例如:对于下面这段代码,在React内部的状态序列是0 -> xiaoming。
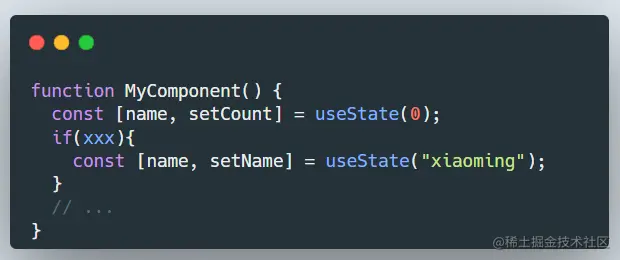
如果在if里调用,那就会出现只有 0 这样的状态序列,就会出现渲染异常:
11.1 为什么Hooks要保证状态序列呢?
因为我们在使用useState声明状态时,只赋给了状态初始值,而并没有给状态加key。
在类组件的时候我们是这样声明状态的:
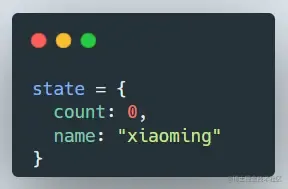
而在函数式组件中,我们是这样声明状态的:
仔细看就会发现,类组件的状态是以一个对象形式储存的,每个状态都有一个key和value相对应。
而在函数式组件中,useState方法只接受了状态的初始值作为参数,并没有key,所以,函数式组件的状态不能以对象的形式存储,只能以线性表的形式存储,比如说数组和链表。实际上,Hooks状态是用链表来存的。
但是无论是数组还是链表,都需要保持顺序,这样才能使每次渲染的序列对得上。
12. React与Vue的diff算法的区别
- react在diff遍历的时候,只对需要修改的节点进行了记录,形成effect list,最后才会根据effect list 进行真实dom的修改,修改时先删除,然后更新与移动,最后插入
- vue 在遍历的时候就用真实dominsertBefore方法,修改了真实dom,最后做的删除操作
- react 采用单指针从左向右进行遍历。当一个集合只是把最后一个节点移到了第一个,react会把前面的节点依次移动
- vue采用双指针,从两头向中间进行遍历。当一个集合只是把最后一个节点移到了第一个,vue只会把最后一个节点移到第一个。总体上,vue的方式比较高效。
- vue对比节点。当节点元素相同,但是classname不同,认为是不同类型的元素,删除重建,而react认为是同类型节点,只是修改节点属性。
13. React严格模式
13.1 什么是严格模式
StrictMode 是一个用来突出显示应用程序中潜在问题的工具。与 Fragment 一样,StrictMode 不会渲染任何可见的 UI。它为其后代元素触发额外的检查和警告。
13.2 作用
- 检测副作用
- 对于在应用中使用已经废弃、过时的方法会发出警告
React 18的文档提到的更多的是purity,即纯度,这其实是函数式编程的理念,这与React 17文档中提到的无副作用是一个意思,react hooks函数式组件实际上就是函数式编程理念的体现。编写纯函数带来了一定的心智负担,但随着开发者对其接受度的提高,新文档中大量使用了purity进行相关描述。文档中提到,纯函数带来了以下优势:
- 多环境运行。例如可以运行在服务端,因为同样的输入,总是对应同样的输出,因此组件可以被其他人复用;
- 减少重复渲染。如果函数组件的输入没有改变,直接复用就好啦,不需要重复渲染。
- 随时中断渲染。在渲染层级较深的组件树时,数据发生了改变,那么React可以马上重新开始渲染,而不用等待过时的渲染完成。
因此StrictMode就是在开发中帮助我们进行检测,保证我们编写的函数组件都是 ‘纯’ 的,这也就解释了为什么开头提到的为什么组件会执行两次,StrictMode会多执行一次,两次执行的结果相同,证明我们编写的的确是纯函数。
14. 服务器端渲染(SSR)
14.1 简介
- 在用户访问时,React SSR(下图中的 SSR with hydration 一类)将 React 组件提前在服务器渲染成 HTML 发送给客户端,这样客户端能够在 JavaScript 渲染完成前展示基本的静态 HTML 内容,减少白屏等待的时间。
- 然后在 JavaScript 加载完成后对已有的 HTML 组件进行 React 事件逻辑绑定(也就是 Hydration 过程),Hydration 完成后才是一个正常的 React 应用。
14.2 弊端
- 服务端需要准备好所有组件的 HTML 才能返回。如果某个组件需要的数据耗时较久,就会阻塞整个 HTML 的生成。
- Hydration 是一次性的,用户需要等待客户端加载所有组件的 JavaScript 并 Hydrated 完成后才能和任一组件交互。(渲染逻辑复杂时,页面首次渲染到可交互之间可能存在较长的不可交互时间)
- 在 React SSR 中不支持客户端渲染常用的代码分割组合React.lazy和Suspense。
而在 React 18 中新的 SSR 架构React Fizz带来了两个主要新特性来解决上述的缺陷:Streaming HTML(流式渲染)和Selective Hydration(选择性注水)
14.3 流式渲染(Streaming HTML)
一般来说,流式渲染就是把 HTML 分块通过网络传输,然后客户端收到分块后逐步渲染,提升页面打开时的用户体验。通常是利用HTTP/1.1中的分块传输编码(Chunked transfer encoding)机制。
15. Babel原理
15.1 什么是Babel
Babel 是一个 JavaScript 编译器。他把最新版的javascript编译成当下可以执行的版本,简言之,利用babel就可以让我们在当前的项目中随意的使用这些新最新的es6,甚至es7的语法。
起初,JavaScript 与服务器语言不同,它没有办法保证对每个用户都有相同的支持,因为用户可能使用支持程度不同的浏览器(尤其是旧版本的 Internet Explorer)。如果开发人员想要使用新语法(例如 class A {}),旧浏览器上的用户只会因为 SyntaxError 的错误而出现屏幕空白的情况。
Babel 为开发人员提供了一种使用最新 JavaScript 语法的方式,同时使得他们不必担心如何进行向后兼容,如(class A {} 转译成 var A = function A() {})。
15.2 Babel运行原理
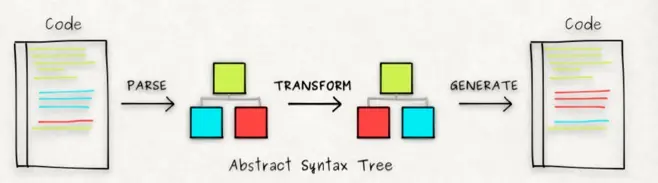
Bebel的转译过程分为三个阶段:
- 解析:将代码解析生成抽象语法树,即词法分析与语法分析两个过程。
- 转换:对抽象语法树进行一系列变换。
- 生成:将转换后的抽象语法树再转换成js代码。
15.2.1 解析
词法分析
词法分析阶段把字符串形式的代码转换为 令牌(tokens) 流。
你可以把令牌看作是一个扁平的语法片段数组:

1 | [ |
每一个 type 有一组属性来描述该令牌:
1 | { |
和 AST 节点一样它们也有 start,end,loc 属性。
语法分析
语法分析阶段会把一个令牌流转换成 AST 的形式。 这个阶段会使用令牌中的信息把它们转换成一个 AST 的表述结构,这样更易于后续的操作。
简单来说,解析阶段就是
1 | code(字符串形式代码) -> tokens(令牌流) -> AST(抽象语法树) |
将上一步的 token 数据进行递归的组装,生成 AST,按照不同的语法结构,来把一组单词组合成对象,这个过程就是语法分析,比如上面的代码,就会生成这样的 AST
1 | { |
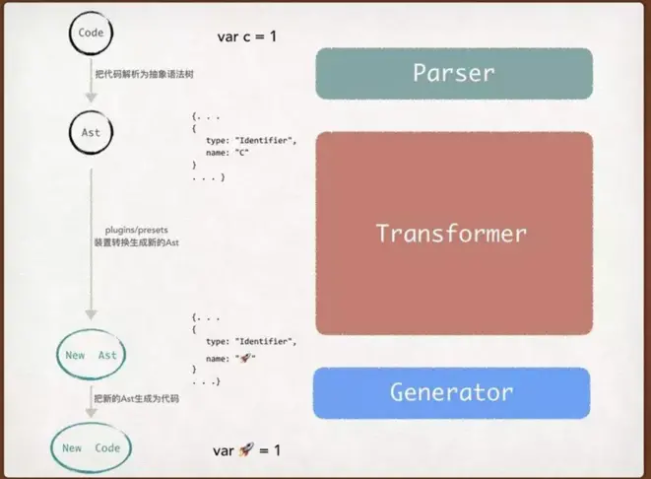
Babel 使用 @babel/parser 解析代码,输入的 js 代码字符串根据 ESTree 规范生成 AST(抽象语法树)。Babel 使用的解析器是 babylon。
15.2.2 转换
转换步骤接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。 这是 Babel 或是其他编译器中最复杂的过程。
Babel提供了@babel/traverse(遍历)方法维护这AST树的整体状态,并且可完成对其的替换,删除或者增加节点,这个方法的参数为原始AST和自定义的转换规则,返回结果为转换后的AST。
15.2.3 生成
代码生成步骤把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)。
代码生成其实很简单:深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
Babel使用 @babel/generator 将修改后的 AST 转换成代码,生成过程可以对是否压缩以及是否删除注释等进行配置,并且支持 sourceMap。
16. JSX 是如何通过 Babel 转换成 JS 代码的
JSX 是 React.createElement 的语法糖,在 All in JS 的世界里,想要保留住 HTML 这种标签语法的结构和层次感,于是有了 JSX,让我们可以在 JS 中编写 HTML,但实际上最终交由浏览器处理的还是 JS。
JSX 会通过 Babel 最终转化成 React.createElement` 的这种形式。
1 | function test() { |
- 第一个参数是要创建的元素的 Tag 值。
- 第二个参数是我们传给元素的 props 值,在生成的 JS 代码中,是以一个普通对象,以键值对的方式存在。
- 第三个参数是 children。
17. React中常用的Hooks有哪些
17.1 uesState:让函数具有维持状态的能力
uesState用来管理状态,在一个组件的多次渲染中,state是共享的。
17.2 useEffect:执行副作用
默认情况下,useEffect会在第一次渲染和更新之后都会执行,相当于在componentDidMount和componentDidUpdate两个生命周期函数中执行回调。
回调函数中可以返回一个清除函数,这是effect可选的清除机制,相当于类组件中componentwillUnmount生命周期函数,可做一些清除副作用的操作。
useEffect接收两个参数:
- 第一个为要执行的函数callback
- 第二个是个可选参数,是一个依赖项数组
依赖项是可选的:
- 如果不指定,那么callback每次都会执行
- 如果指定了,那么只有依赖项中的值发生了变化的时候,才会执行callback
17.3 uesMemo与uesCallback
uesMemo的使用:缓存计算结果

useCallback的使用:缓存回调函数

相同点:
- 两者接收的参数都是一样的,第一个参数表示一个回调函数,第二个表示依赖的数据。
- 两者都是仅仅当依赖的数据发生变化时, 才会重新计算结果,也就是起到缓存的作用。
- 都是用来作为性能优化。
不同点:
useMemo 计算结果是 return 回来的值, 主要用于缓存计算结果的值 ,应用场景如: 需要计算的状态
useCallback 计算结果是函数, 主要用于缓存函数,应用场景如: 需要缓存的函数。
因为函数式组件每次任何一个 state 的变化, 整个组件都会被重新刷新,一些函数是没有必要被重新刷新的,此时就应该缓存起来,提高性能,减少资源浪费。
useCallback 的功能其实是可以用 useMemo 来实现的。当我们在useMemo中return的是一个函数的时候,实际上与useCallback的功能是相同的。所以说useMemo与useCallback有异曲同工之处。
17.4 uesRef:在多次渲染之间共享数据
可以把 useRef 看作是在函数组件之外创建的一个容器空间。在这个容器上,可以通过唯一的 current 属性设置一个值,从而在函数组件的多次渲染之间共享这个值。
使用 useRef 保存的数据一般是和 UI 的渲染无关的,因此当 ref 的值发生变化时,是不会触发组件的重新渲染的,这也是 useRef 区别于 useState 的地方。
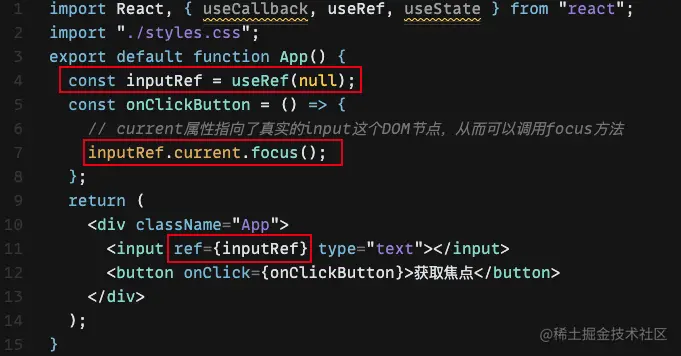
可以通过useRef保存某个 DOM 节点的引用。 结合 React 的 ref 属性和 useRef 这个 Hook,就可以获得真实的 DOM 节点,并对这个节点进行操作。
功能具体例子:你需要在点击某个按钮时让某个输入框获得焦点
17.5 useContext:定义全局状态
React 组件之间的状态传递只有一种方式,那就是通过props。这就意味着这种传递关系只能在父子组件之间进行。
而如果需要跨层级的话,React 提供了 Context 这样一个机制。
Context这个机制,能够让所有在某个组件开始的组件树上创建一个 Context。这样这个组件树上的所有组件,就都能访问和修改这个 Context 了。
一个 Context 是从某个组件为根组件的组件树上可用的,所以需要有 API 能够创建一个 Context,就是React.createContext。

React.createContext 创建出来的值具有一个 Provider 的属性,一般是作为组件树的根组件。
这个根组件中可以通过value属性对数据进行传递。
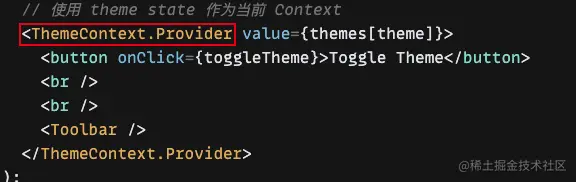
这样的话,在后代的组件中通过useContext就可以接收到上方通过value传来的值,从而进行一系列的操作。

18. React Diff原理
diff算法就是更高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处。
react中diff算法主要遵循三个层级的策略:
- tree层级
- component 层级
- element 层级
18.1 tree层级
只会对相同层级的节点进行比较。
只有删除、创建操作,没有移动操作,如下图:
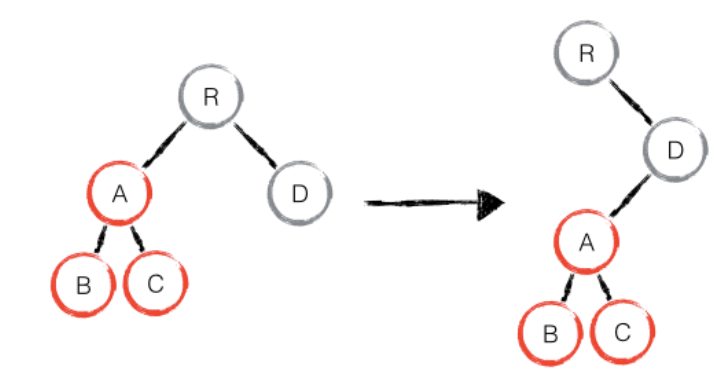
react发现新树中,R节点下没有了A,那么直接删除A,在D节点下创建A以及下属节点。
上述操作中,只有删除和创建操作。
18.2 component层级
如果是同一个类的组件,则会继续往下diff运算,如果不是一个类的组件,那么直接删除这个组件下的所有子节点,创建新的。
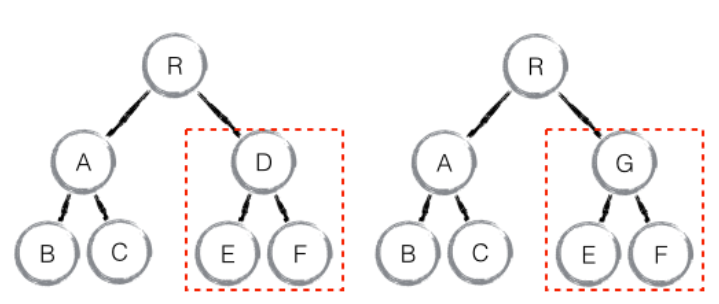
当component D换成了component G 后,即使两者的结构非常类似,也会将D删除再重新创建G。
18.3 element层级
对于比较同一层级的节点们,每个节点在对应的层级用唯一的key作为标识
提供了 3 种节点操作,分别为 INSERT_MARKUP(插入)、MOVE_EXISTING (移动)和 REMOVE_NODE (删除)。
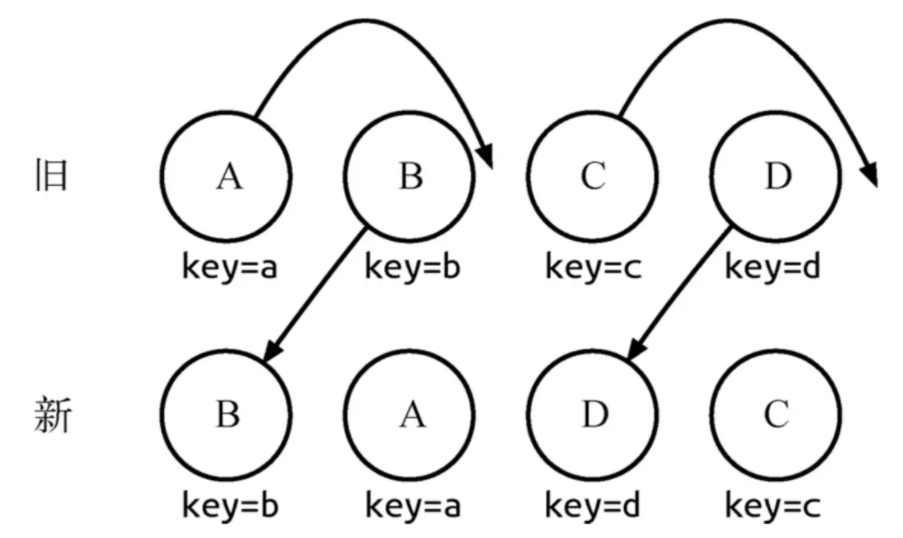
通过key可以准确地发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置。
19. 虚拟DOM中key的作用
简单的说:key是虚拟DOM对象的标识,在更新显示时key起着极其重要的作用
详细的说:当状态中的数据发生变化时,react会根据【新数据】生成【新的虚拟DOM】,随后react进行【新虚拟DOM】与【旧虚拟DOM】的diff比较,比较规则如下:
旧虚拟DOM中找到了与新虚拟DOM相同的key:
若虚拟DOM中内容没变,直接使用之前的真实DOM
若虚拟DOM中内容变了,则生成新的真实DOM,随后替换掉页面中之前的真实DOM
旧虚拟DOM中未找到与新的虚拟DOM相同的key
- 根据数据创建新的真实DOM,随后渲染到页面
20. 用index作为key可能会引发的问题
若对数据进行:逆序添加、逆序删除等破坏顺序的操作:
- 会产生没有必要的真实DOM更新 ==> 界面效果没问题,但效率低
如果结构中还包含输入类的DOM
- 会产生错误DOM更新 ==> 界面有问题
注意,如果不存在对数据的逆序添加、逆序删除等破坏顺序的操作,仅用于渲染列表用于展示,使用index作为key是没有问题的
1 | <script type="text/babel"> |

这时,逆序添加后,key对应的标签里的数据全部都变了,所以会引起所有li标签的重新渲染。